本文主要分析 Leela Zero (v0.15, #9e903ed) 自对弈部分的代码
自对弈(Self Play/autogtp)
Leela Zero 自对弈部分的代码在 autogtp 目录下。入口文件为 main.cpp,主要的逻辑在 Management.cpp 文件中。
Main
自动下棋的主要逻辑可以总结为如下流程图。
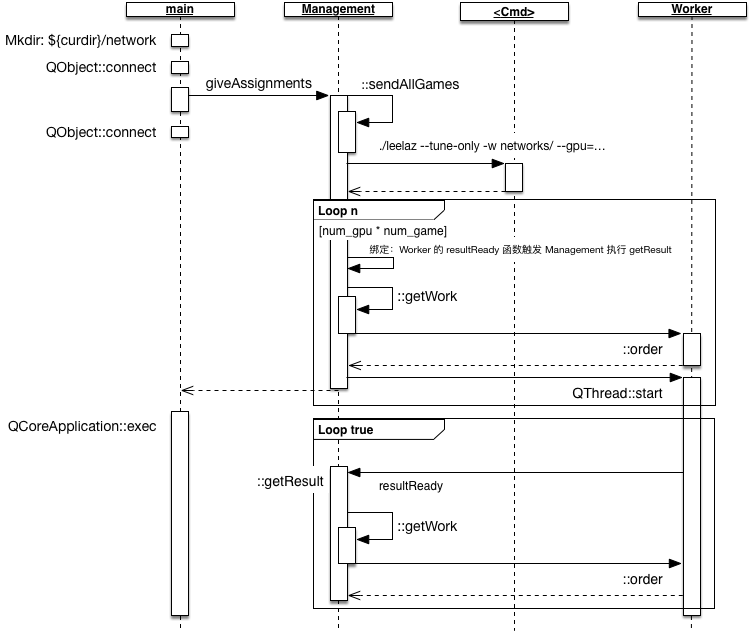
- STEP 1:main 函数启动,首先检查执行程度的目录下是否有 networks 文件夹,没有则创建一个,networks 文件夹存储模型参数。 之后绑定各种信号量,主要是在程序退出时进行数据备份和清理,可以参阅代码,在此不再细讲。
STEP 2:main 函数调用 Management::giveAssignments 函数分配初始任务。 在 giveAssignments 中,首先执行 sendAllGames(此处省略解读),然后调用启动一个单独的线程执行 bash 命令,如下所示
1
./leelaz --tune-only -w networks/dec5b9d88877fe876a308b42370335c8f5465235d0104c889bdda3b42993aa28 --gpu=0
之后,创建工作线程。每个 Worker 线程将其产生的 resultReady 信号与 Management 中的 getResult 函数进行绑定。 绑定通过调用 QT 的 API 函数 QObject::connect 完成,对 QObject::connect 的解释可以参考[1]。
- STEP 2.1 提交作业:在线程启动前,会先向每个 Worker 线程提交一个作业(Worker::order),这个作业调用 Management::getWork 获取, 具体过程参考 Job-Assignment;
- STEP 2.2 启动线程:Worker 线程启动后,会先执行初始化时提交的作业, 这个作业执行完成后会由 Worker 主动发起一个 resultReady 信号给 Management。 根据之前的信号绑定关系,Management 接收到 resultReady 信号后会调用 Management::getResult 函数进行处理。 在 Management::getResult 函数中会再次调用 getWork 函数获取作业,并提交给响应的 Worker 进行处理。 线程反复执行提交对弈作业,直到用户程序主动停止主进程的执行。
Job Assignment
Autogtp 作业都是通过请求远程服务器获取对弈的模型参数和对弈作业的类型,完成对弈作业后将执行的数据提交到服务器端。 作业执行的流程可有如下顺序图表示
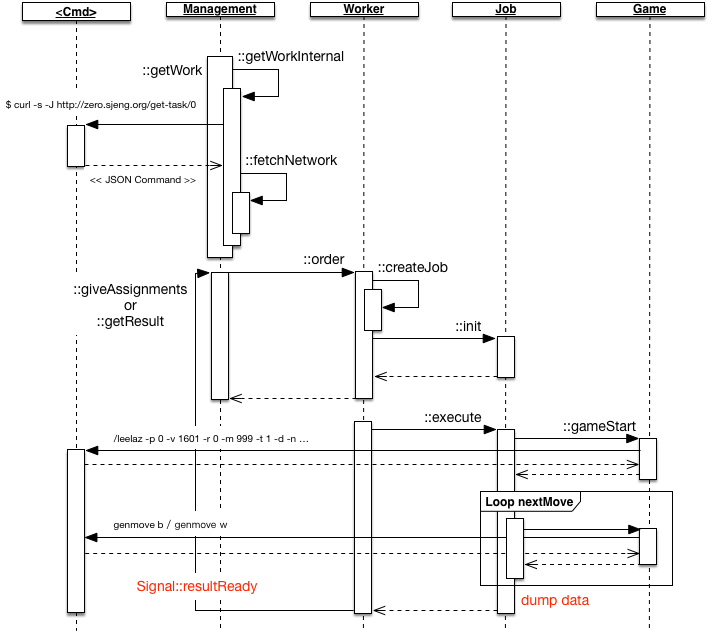
执行 Management::getWorker 后会经过如下步骤
STEP 1:调用 Management::getWorkInternal 函数,autogtp 调用命令行函数获取作业,其类似于执行如下命令
1
curl -s -J http://zero.sjeng.org/get-task/16
可请求的作业有三种类型,均匀以 JSON 格式的数据返回,分别是:
selfplay:进行同一个模型的自对弈,即黑白棋采用的推理参数相同,其 JSON 格式的作业数据如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{
"cmd": "selfplay",
"hash": "dec5b9d88877fe876a308b42370335c8f5465235d0104c889bdda3b42993aa28",
"hash_gzip_hash": "0fff7d2ea27611eec2fbeeab103c95770742437bb9e6a0ccd0af15bc9d3e23d1",
"minimum_autogtp_version": "16",
"minimum_leelaz_version": "0.15",
"options": {
"noise": "true",
"playouts": "0",
"randomcnt": "999",
"resignation_percent": "5",
"visits": "1601"
},
"options_hash": "b37dca",
"random_seed": "5266686459798233275",
"required_client_version": "16"
}match:进行两个模型之间的对弈,可以比较两个模型之间的好坏,其 JSON 格式的作业数据如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15{
"cmd" : "match",
"white_hash" : "223737476718d58a4a5b0f317a1eeeb4b38f0c06af5ab65cb9d76d68d9abadb6",
"black_hash" : "92c658d7325fe38f0c8adbbb1444ed17afd891b9f208003c272547a7bcb87909",
"options_hash" : "c2e3"
"required_client_version" : "5",
"leelaz_version" : "0.9",
"random_seed" : "1",
"options" : {
"playouts" : "1000",
"resignation_percent" : "3",
"noise" : "false",
"randomcnt" : "0"
}
}wait:等待,其 JSON 格式的作业数据如下
1
2
3
4{
"cmd" : "wait",
"minutes" : "5",
}
STEP 2:执行自动对弈
autogtp 针对每种作业都定义了不同的执行逻辑,
selfplay:被定义为 ProductionJob。启动一个
leelaz进程,执行genmove b下黑棋,genmove w下白起。 启动leelaz的命令如下1
2
3
4./leelaz -p 0 -v 1601 -r 0 -m 999 -t 1 -d -n --noponder \
-s 4893736926019914355 \
--gpu=4 -g -q \
-w networks/dec5b9d88877fe876a308b42370335c8f5465235d0104c889bdda3b42993aa28参数解释如下
- -p: Weaken engine by limiting the number of playouts. Requires –noponder.
- -v: Weaken engine by limiting the number of visits.
- -r: Resign when winrate is less than x%. -1 uses 10% but scales for handicap.
- -m: Play more randomly the first x moves.
- -t: threads
- -d: Don’t use heuristics for smarter passing.
- -n: Enable policy network randomization.
- -noponder: Disable thinking on opponent’s time.
- -s: Random number generation seed.
- -gpu: ID of the OpenCL device(s) to use (disables autodetection).
- -g: Enable GTP mode.
- -q: Disable all diagnostic output.
- -w: File with network weights.
match:被定义为 ValidationJob。启动两个
leelaz,每个leelaz分别载入不同的对弈参数。其对弈过程如下假设运行白棋的为 leelaz_w,运行黑棋的 leelaz_b
- 当 leelaz_w 调用
genmove w执行了一步操作后,会输出该操作的步如 C14; - 在 leelaz_b 中执行
play white C14,然后调用genmove b执行下一步操作,输出操作步如 E17; - 在 leelaz_w 中执行
play black E17,然后调用genmove w执行下一步操作,输出操作步如 H18; - 重复上述两个步骤,直到一方认输。
- 当 leelaz_w 调用
wait:被定义为 WaitJob。执行 sleep 操作。
STEP 3:导出数据;
STEP 4:发送 resultReady 信号,调用 Management::getResult 请求下一个作业,重复 STEP1 - STEP4 的操作。 在 getResult 函数执行过程中,会上传模型数据。