前段时间用 Express (PugJS) + MongoDB + Scrapy 建了一个视频索引网站。现在简单总结一下。
搭建网站
前端开发
首先,不得不说使用 MongoDB 建站是一件很方便的事情。后台 Model 有任何改动,只需要在 mongoose 加一个字段就可以了,相比于关系型数据库的严格类型约束,Object DB 更适合迭代开发。不过在性能上 mongodb 在后期有些吃力,特别是服务器配置不高的时候,mongodb 对内存的压力还是不小,不过这都是后话。在实现 search 和 related document 功能的时候,偷懒使用 MongoDB 的全文检索功能,性能不高,基本可以,适用于原型设计。
其次,Express 管理服务端逻辑。我采用传统的 MVC 将文件分为 controller、model、view 三个部分。controller 负载页面响应和数据获取,model 就是定义 mongoose 中 document 的字段,以及一些基本的存储逻辑(比如用户登录的密码验证,加密等操作),view 这部分我采用的 pugjs 进行前端页面渲染,pugjs 本质上还是 javascript 所以操作前端页面按照 JS 的逻辑来写就行了,不过开发过程中自己会把很多字符串处理逻辑都写在 PUG 中,感觉不是太好。
再次,就是前端 JS 的 IE 兼容问题。因为习惯使用 es2015 来写,在实际运行的时候发现在 chrome、firefox 下跑的很好,但是在 IE 上就出现各种问题。解决方法是用 babel 的 es2015-ie 插件进行兼容转换。
最后,Mobile 和 Destop 的支持,采用 Bootstrap 进行响应式布局,对于 CSS 不是特别熟悉,所以没有过多的研究响应式布局的细节。
数据获取
建站的前提是有稳定的数据源,因为自己不做 CMS,所以内容方面全部依赖爬取站点的内容质量。在此,不做详述。
数据爬取使用 scrapy 框架,只是使用了基本的功能。对于分布式、IP 池等没有涉及。每个站点都写了一个 Spider。从 Spider 到 Server Model 还有一段路要走,也就是说爬下来的时候需要清洗才能入库呈现。这部分的 pipeline 我是这么设计的:
- scrapy 爬取元数据,包括视频播放连接和元信息两部分;
- 经过 join 将视频信息和元信息进行合并,然后剔除不符合要求的数据,进入 model 库;
- 对数据进行回查,相当于是对 model 库进行清洗,主要就是剔除失效的视频连接,这部分可以定期处理(一个简单粗暴的 CMS 功能)。
写在最后
至此,站点就被搭建起来了,是不是很简单。因为没有数据维护(或者可以说是很简单的数据维护),一切数据依赖被爬取站点的数据质量。这种寄人篱下的站点建设方法不知道什么时候就会因为目标网站的升级需要更新自己的 spider 逻辑。
而且,随着 mongodb 中的数据越来越多,查询性能和 search 性能都在下降(前提是服务器不升级,512 MB 内存 1 CPU,6万多条记录,related search 的响应时间在 10-20 sec,find by index 的响应时间在 1-3 sec, findById 的的响应时间在 200-600 ms)。
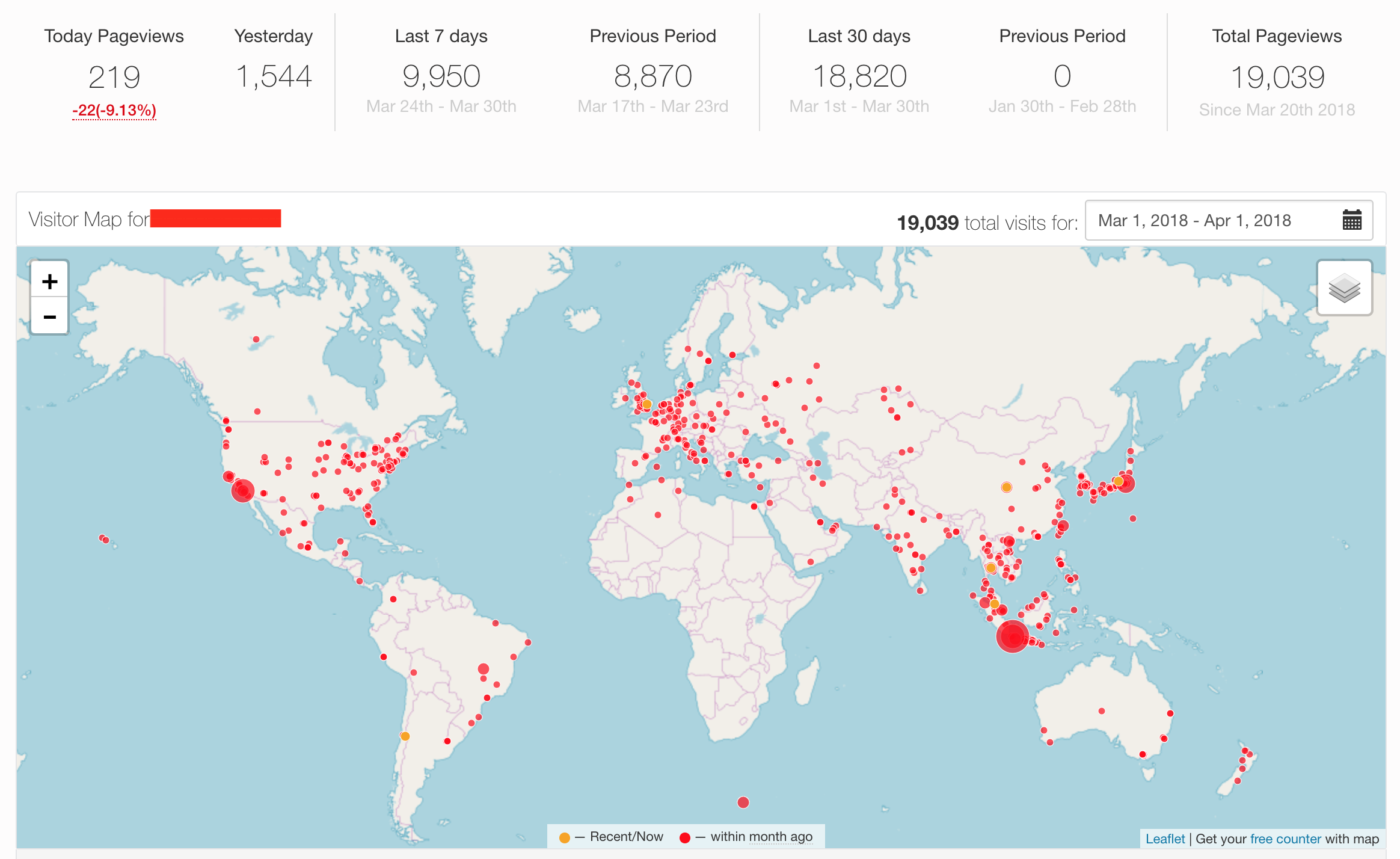
此外,网站监控使用第三方服务,包括 google analysis、whos.amung.us、histats、clustrmaps 等,whos 主要监控实时的视频播放人数,histats 监控网站的访问,clustrmaps 这个主要是对旧版页面的监控。google analysis 分析整个网站的访问情况。
SEO:设置了 sitemap 和 robots,对页面的 meta 进行了简单的设计,但效果不是太理想,现在也在摸索。
反爬虫:还没做。
未来发展
这个站点就这样了吧,作为一个练手的站点,未来最多也就是更新数据源了。不过以后想用 vue 或者 react 写个单页面的网站。将前端和后端数据完全分离,现在 pug 渲染的时候,还是会将一部分 control 逻辑混写在 view 中。期待前后端数据和渲染的完全分离。
最后贴一个现在 clustrmaps 统计的访问情况,以示纪念。